The Algolia A/B testing feature helps you set up an A/B test to assess whether your search strategy is successful. Reading the results and trends from your test might seem straightforward, but there are several things to bear in mind when interpreting results.
Understanding how A/B testing works
How results are computed
A/B test results are computed from click-through and conversion rates based on the events you send to the Insights API. This computation can lead to different results from what you have on your business data.
To learn more about these rates, see:
Automatic outlier exclusion
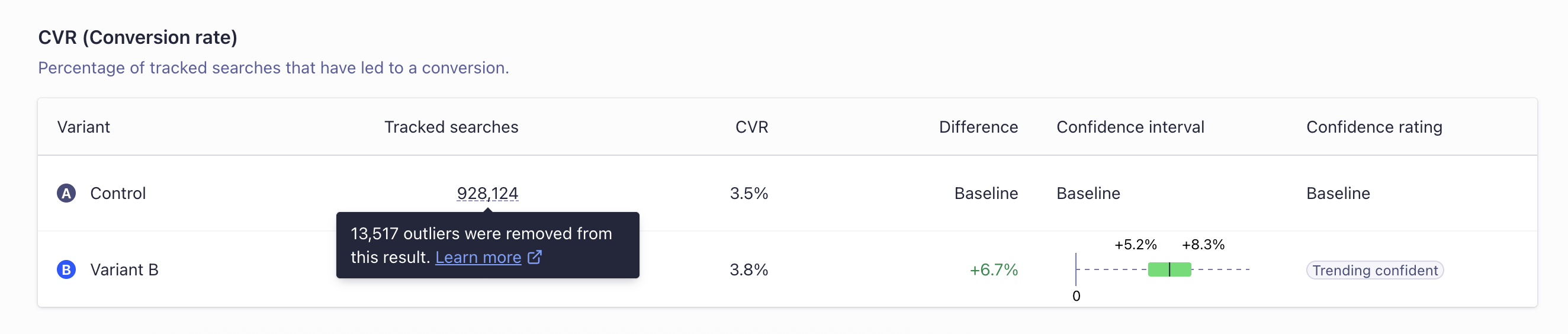 When A/B testing, outlier traffic can skew the results and make them unrepresentative of real user traffic. Algolia’s A/B testing feature automatically excludes outlier users when calculating A/B test result metrics.
A user qualifies as an outlier if the number of tracked searches performed by that user is 7 standard deviations (σ) more than the mean (μ) number of searches per user for the entire A/B test. A tracked search is a search with the
When A/B testing, outlier traffic can skew the results and make them unrepresentative of real user traffic. Algolia’s A/B testing feature automatically excludes outlier users when calculating A/B test result metrics.
A user qualifies as an outlier if the number of tracked searches performed by that user is 7 standard deviations (σ) more than the mean (μ) number of searches per user for the entire A/B test. A tracked search is a search with the clickAnalytics parameter set to true.
To check the number of outliers and the number of tracked searches that were removed from each variant, hover over the Tracked Searches and Tracked Users counts for each variant.
For example, when a bot scrapes your site, it can trigger search requests without clicking or converting.
If this bot were assigned to the B variant for an A/B test, it would artificially increase the number of tracked searches.
This increase would cause a larger-than-intended decrease in click and conversion rates for the test, even when an increase would be seen for real users.
With outlier removal, these significant, undesirable sources of traffic will be excluded. This exclusion ensures that results will more accurately represent real-user searches and the impact of any changes in the variant.
Revenue winsorizing
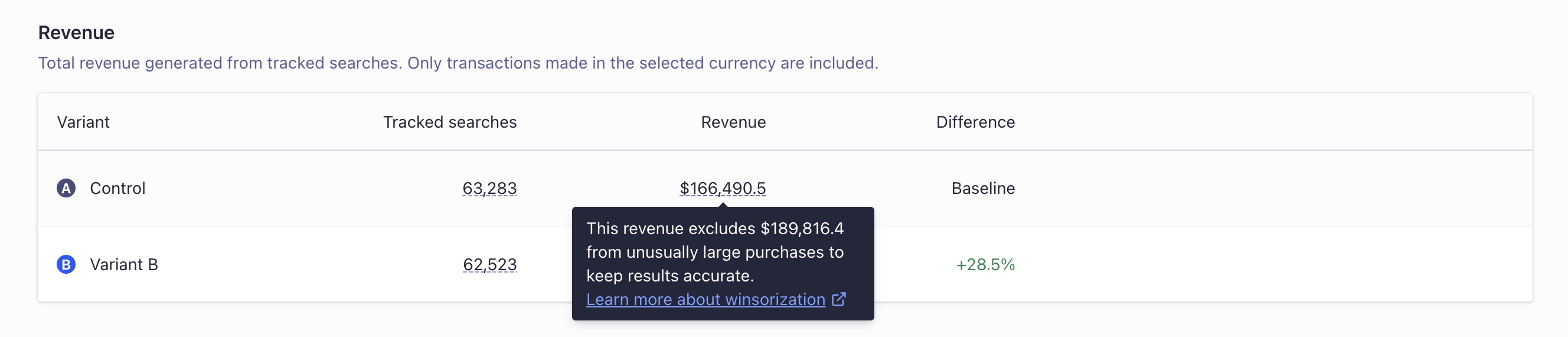 Winsorizing is a statistical technique that limits extreme values in data to reduce the effect of outliers.
Instead of removing an outlier, the value is still included as a data-point, but is constrained to a reasonable amount.
In the context of Algolia A/B testing, winsorizing is applied to revenue data to ensure that outlier purchases don’t skew the results.
When calculating the revenue for each variant, Algolia caps all purchases at the global 99th percentile.
This means that unusually large purchases don’t disproportionately affect the overall confidence determination for that variant, and instead will be treated as a purchase equal to the 99th percentile value.
For example, if a user makes a purchase for $1,000, and the 99th percentile for all purchases is $100 (including the $1,000 purchase), then the $1,000 purchase will be counted as $100 for the purposes of calculating the revenue for that variant.
Confidence is then determined based on the adjusted revenue values, so extreme outlier purchases have a smaller effect.
Winsorizing is a statistical technique that limits extreme values in data to reduce the effect of outliers.
Instead of removing an outlier, the value is still included as a data-point, but is constrained to a reasonable amount.
In the context of Algolia A/B testing, winsorizing is applied to revenue data to ensure that outlier purchases don’t skew the results.
When calculating the revenue for each variant, Algolia caps all purchases at the global 99th percentile.
This means that unusually large purchases don’t disproportionately affect the overall confidence determination for that variant, and instead will be treated as a purchase equal to the 99th percentile value.
For example, if a user makes a purchase for $1,000, and the 99th percentile for all purchases is $100 (including the $1,000 purchase), then the $1,000 purchase will be counted as $100 for the purposes of calculating the revenue for that variant.
Confidence is then determined based on the adjusted revenue values, so extreme outlier purchases have a smaller effect.
Looking at your business data
As Algolia A/B testing is specific to search, the focus is on search data. It’s best to look at the A/B test results in light of your business data to assess your test’s impact. For example, you can cross-reference search and revenue data to compute your interpretation of conversion or to look at custom metrics.
When to interpret what
Algolia A/B tests begin to show data in the dashboard after either 7 days have passed or 20% test completion, whichever happens first.
This is because the initial data from A/B tests can be unstable, and making comparisons before the test reaches 7 days or 20% completion could lead to inaccurate conclusions. Even if some data is visible, it doesn’t mean that it’s the right time to make decisions based on them.
Here are some factors you should consider before interpreting the results of an A/B test.
Can you be confident in the data?
Before you interpret results and draw conclusions on what steps to take next, ensure that there is confidence. The confidence indicator helps you assess whether the results are the product of chance or an accurate representation of how your users behave.
During an A/B test, the confidence value is just the measure of a trend.
While the test is ongoing, confidence may vary, so you should only make tentative conclusions.
Once the A/B test is complete, the confidence value is final and will no longer change.
Is there enough data?
As the number of searches increases, confidence increases, and the results become more reliable.
Run your test for as long as possible to ensure you have enough data to maximize confidence.
Is the split off?
When setting your A/B test, you assign a percentage of search traffic to each variant (by default, 50/50). The expected traffic split should be reflected in the displayed search count. For most A/B test configurations, the search count for each variant should match the traffic split. If there’s a noticeable discrepancy, there’s probably an issue.
For example, you could have a 50/50 split, ending up with 800,000 searches on one side and 120,000 on the other. The results are unreliable if you see a difference higher than 20% from the expected number.
Algolia attempts to identify and ignore any unusual data (outliers) when calculating A/B test results.
But, if there’s a big difference between what you thought the traffic would be like and what it is, investigate your A/B test setup.
This will help you figure out why there’s a mismatch.
How to interpret confidence intervals?
Each confidence interval is comparing the variant with control, and Algolia doesn’t show any variant to variant comparisons. Algolia implements a relative confidence interval, which normalizes the control to zero. Over time you should see the confidence interval decrease. A variant is statistically significant when the colored band doesn’t overlap zero.
Troubleshooting
If you believe something’s wrong with your A/B test results, there are some checks to identify what could be the root cause.
Analytics and events implementation
Since A/B tests rely on Click and Conversion events, ensure you’ve properly implemented them.
For example, you might want to check the following:
- Are you catching both click-through and conversion rates?
- Are there enough events on popular searches?
- Are there any errors in the Insights API Logs within the Monitoring section of the Algolia dashboard?
Seasonality
Sales or holidays (such as Black Friday) can affect your test, with more out-of-stock items, for example.
If you see unexpected results, check whether you’ve been conducting the A/B test during a special period.
For more information, see A/B test implementation checklist.
A/B test in a Dynamic Re-Ranking context
If you have launched an A/B test to evaluate Dynamic Re-Ranking’s effect, there are additional considerations:
- Make sure to launch the A/B test through the Dynamic Re-Ranking interface. If it’s not the case, Dynamic Re-Ranking must be opted-in for the being tested.
- If using a replica, ensure re-ranking does have an impact: you should have queries re-ranked for this index. If not, change its events source index to the primary index for Dynamic Re-Ranking.
- Check whether Personalization is also enabled for the index you’re testing. The analysis isn’t optimal when Personalization is enabled: it counts traffic towards Dynamic Re-Ranking when it probably doesn’t matter for a given percentage of the traffic. Indeed, as soon as a Personalization is detected, Dynamic Re-Ranking no longer has any effect.
- Dynamic Re-Ranking isn’t optimized for particular use cases like marketplaces with short-lived items, for instance. If this is your use case, you may see A/B test results that aren’t satisfactory.
If you’re using distinct,
items are regrouped so Dynamic Re-Ranking has a lesser impact.
The data is inconclusive
The confidence calculation involves ratios, and there’s no guarantee that confidence will be achieved even if the test is set up as intended.
Your data could be trending confident one day but inconclusive some days later.
Some of the reasons for this are:
- Variability in the Data: A/B test results can be quite volatile when the sample size is small. It’s possible that at the start of the test, the observed difference was due to chance, and as more data was collected, the true difference (if any) became clearer.
- External Factors: External events could influence the behavior of users. For example, if you’re testing changes on an ecommerce site, a major holiday, sale, or event could skew results temporarily.
- Sampling Bias: If there’s any change in the type or behavior of users during the test (for example, a change in traffic source, a product release, or a marketing campaign), it can influence results.
Check the following if the A/B test doesn’t achieve confidence:
- Review Test Setup: Ensure that there have been no technical issues or changes during the test that could have affected the results. Make sure the groups are still being split as configured, and no outside influences have been introduced.
- Consider external factors: were there any external events or factors that could have influenced the results? Understanding these can help in interpreting confidence.
- Increase Sample Size: If the sample size is small, continue running the test to collect more data. A larger sample size (for example, by running the test for a longer period of time) can give more accurate and stable results.
- Adjust the split: if the sample size is large, but confidence is still low, consider adjusting the split to increase the number of users in each group. For example, if the split is 70/30, try 60/40 or 50/50. Uneven splits can be useful for minimizing exposure to a high-risk change but also require a larger sample size to reach confidence.
Click-through rate is going up and conversion rate is going down
This probably means that top search results don’t convert. Potential causes include out-of-stock products, items with the wrong picture, misleading descriptions, or unavailable sizes. In such cases, you can use filtering to eliminate unavailable products, fix the relevance implementation to prioritize certain items or clean up your data.
If possible, you should also look at your own business intelligence metrics to confirm/deny the results you’re seeing. If you’re looking at revenue, for instance, what’s the impact of the A/B test?
Click-through and conversion rates are both going down
You might reach the point where you have been through all the possible checks to see if there’s something wrong with your A/B test and Insights API implementation, and nothing seems to explain the results. Perhaps the settings you’re testing aren’t a good strategy for your search: keep iterating to find a successful strategy.
Contact the Algolia support team for further help. Last modified on June 19, 2026