- The crawl status (
FailedorSkipped) and category (Extraction) - An error message
- Missing or attributes
Domain wasn’t crawled
No pages from a particular domain appear in your crawler’s records.Solution
To ensure that the crawler can access and index your site, check that:- You’ve added and verified the domain.
- The Crawler’s IP address (34.66.202.43) is in your site’s allowlist.
-
The Crawler’s user agent is in your site’s robots.txt file.
When fetching pages, the Crawler identifies itself with the user agent:
Algolia Crawler/xx.xx.xx, wherexx.xx.xxrepresents a version number. To allow crawling of your site, add the following to yourrobots.txtfile:User-agent: Algolia Crawler - You’ve adjusted the settings for custom security checks. If you’ve set up extra security measures on your site, for example with nginx, you might need to update those settings to ensure the crawler isn’t blocked.
- You’ve verified every domain you would like to crawl. Algolia needs proof that you or your organization owns the domain, whether it’s on your servers or hosted. The Crawler can only visit sites that you’ve verified belong to you.
-
You’ve configured site protection systems to recognize the Crawler.
If your site uses tools like Cloudflare or Google Cloud Armor to block unwanted visitors,
you must add the Crawler’s IP address or user agent to your allowlist.
Otherwise, the Crawler may be treated as an intruder: if so,
you’ll see
403status errors and the Crawler could be blocked.
A page wasn’t crawled
A page within a domain wasn’t crawled but others were.Solution
The reason why a page wasn’t crawled can vary. Check that:- The crawling process has finished. Crawling a big site can take time: check the progress from the Crawler page.
- The page is linked from the rest of your site.
Ensure you can trace a path from the
startUrlsto the missing page. It should either be reachable from these starting points or listed in your sitemap. If not, add the missing page as a start URL. - You’ve given the crawler the correct path.
Ensure the page matches one of the
pathsToMatchyou’ve told the crawler to look for. - You haven’t instructed the crawler to ignore the page.
If the page matches an
exclusionPatterns, the crawler ignores it. - The page requires a login.
If so, add the
loginparameter to your configuration.
Missing attributes
Attributes that you expect to see in your crawler’s records are missing.Investigation
Verify what might be missing:- Review the records in the Algolia index and check for missing attributes.
- Open the Crawler’s Editor and find the action responsible for extracting records from that content type (for example, a blog post). If your configuration has more than one action, identify the correct action by checking its
pathsToMatch. For example, an action that extracts blog posts looks something like:pathsToMatch: ["https://blog.algolia.com/**"] - Check if the action actually extracts the requested attribute. For example, the following action should collect author names from blog posts, but it doesn’t.
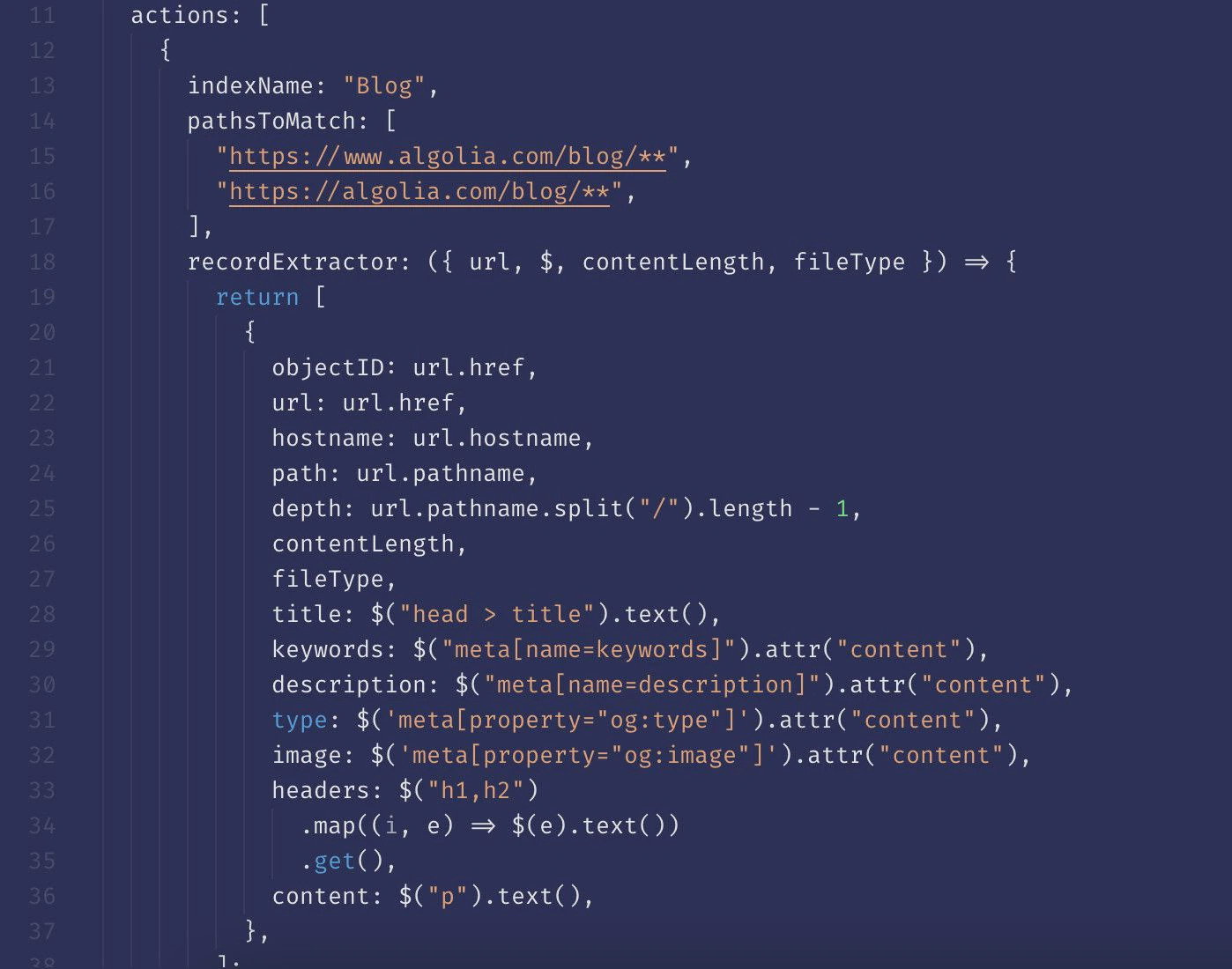
Solution
- Find a page on your site that fully represents the content type you want to extract. For example, a blog post with complete title, subtitle, author, blog content, and date published.
- Inspect the page to determine the best way to extract the content: JSON-LD, Meta Tag, or CSS selectors.
- In the Crawler’s Editor, update the appropriate
recordExtractorto extract the missing attribute. - Use the URL tester to check that the updated configuration works and you’re collecting what you need.
recordExtractor, retry the crawl and verify that everything works.
For more information, see:
Debug CSS selectors
An attribute you want to extract with a CSS selector doesn’t appear in your crawler’s records.Investigation
Use your browser developer tools to type a CSSquerySelector command directly into the console:
JavaScript
console.log command to an action’s recordExtractor.
For example:
JavaScript
Solution
- Update the appropriate
recordExtractorto extract the missing attribute. - Save your changes.
recordExtractor,
retry the crawl and verify that everything works.
JavaScript is required
One or more pages weren’t crawled. To prioritize speed, the Crawler doesn’t evaluate JavaScript by default. This can cause differences between the dynamically generated content on the site and the static HTML that the crawler indexed.Investigation
To see how a page looks without JavaScript, turn off JavaScript for your browser. You might notice that some information, like an author name, disappears without JavaScript.Solution
Enable JavaScript for the appropriate action with therenderJavaScript parameter.
After updating your action, retry the crawl and verify that everything works.
Canonical URL omissions
Due to a canonical URL error a page wasn’t crawled. This is indicated by an error message:Canonical URLCanonical URL - Not processed
Solution
If you want to crawl all pages and your site has canonical URLs, setignoreCanonicalTo to true.
After updating your configuration,
retry the crawl and verify that everything works.
Crawler data limitations
The Crawler imposes certain limits on extracted data, and if you go beyond these limits, it will generate an error message.Solutions
After modifying your data, retry the crawl and verify that everything works.
Crawler technical limitations
The Crawler has limitations and if you exceed them, an error message is shown:Extractor returned too many linksExtractor timed outPage is too big
Extractor returned too many links
A page returned more than the maximum number of links:- 5,000 per page
- 50,000 per sitemap
Solution
Edit the source page to split it into several pages or remove some of its links. After modifying your source pages, retry the crawl and verify that everything works.Extractor timed out
The page took too long to crawl. This may be due to:- A mistake, such as an infinite loop, in the crawler configuration.
- Page is too big.
Solution
Review your crawler configuration. After modifying your crawler configuration, retry the crawl and verify that everything works. If the issues persist, see Page is too big.Page is too big
A page may be too big to fit in the crawler’s memory.Solution
You have several options:- Reduce page size
- For pages rendered with JavaScript: avoid loading too much data.
- Ignore the page when crawling.
Responses to user agents
If you find that some information isn’t showing up as it should, it may be due to your site’s response to different user agents.Investigation
Check to see if the problem is due to the Algolia user agent by testing with a browser extension or curl. Send requests to the same site with different user agents and compare the differences between site responses. For example, withcurl:
Crawler user agent
Crawler user agent
Command line
Firefox (macOS) user agent
Firefox (macOS) user agent
Command line
Solution
Configure your site to ensure it doesn’t rely on specific user agent strings to render content.RSS feeds don’t generate content
RSS feed pages aren’t crawled.Solution
This is expected behavior. RSS feeds themselves don’t contain content. When the crawler encounters an RSS feed, it identifies and crawls all thelink tags in the RSS files
but doesn’t generate records directly from those RSS feeds.