Limitations
Because it’s difficult to translate non-HTML documents into HTML, there are limitations:- PDF documents can break if it’s exported with an unknown font.
- The transformed HTML has little semantic value: headings, paragraphs, and lists in the original document might not be marked in the HTML. This makes good relevancy hard to achieve.
- Document indexing is slower than classic HTML indexing.
- Language detection isn’t available.
Enable document extraction
To enable document extraction, add thefileTypesToMatch
parameter to at least one of your crawler’s actions.
For a list of supported file types, see Supported file types.
The document’s transformed HTML is stored in the recordExtractor.$ parameter.
The file type is stored in the recordExtractor.fileType parameter.
JavaScript
Sample crawler configuration
For an example configuration for document extraction, seeconfig.documents.js on GitHub.
Supported file types
The metadata shown in these examples might not be included on every page.
PDF documents
- Associated extension:
.pdf fileTypesToMatch:pdf
.pdf file, Tika exposes the following HTML which the crawler then passes to your recordExtractor.

HTML
Microsoft Word documents
- Associated extensions:
.doc,.docx fileTypesToMatch:doc
.doc file, Tika exposes the following HTML, which the crawler then passes to its recordExtractor.
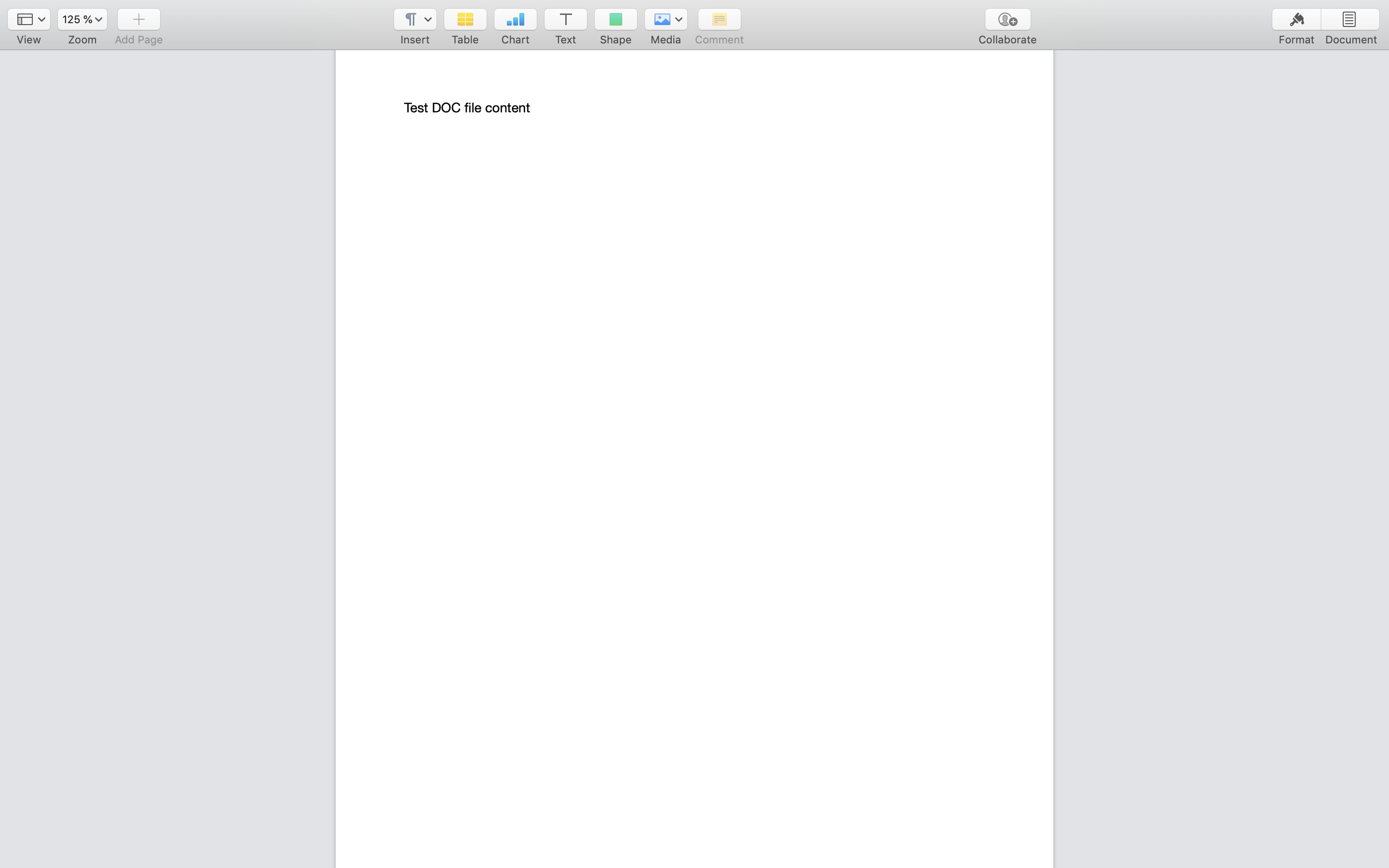
HTML
OpenDocument text documents
- Associated extension:
.odt fileTypesToMatch:odt
Microsoft Excel spreadsheets
- Associated extensions:
.xls,.xlsx fileTypesToMatch:xls
.xls file, Tika exposes the following HTML, which the crawler then passes to its recordExtractor.
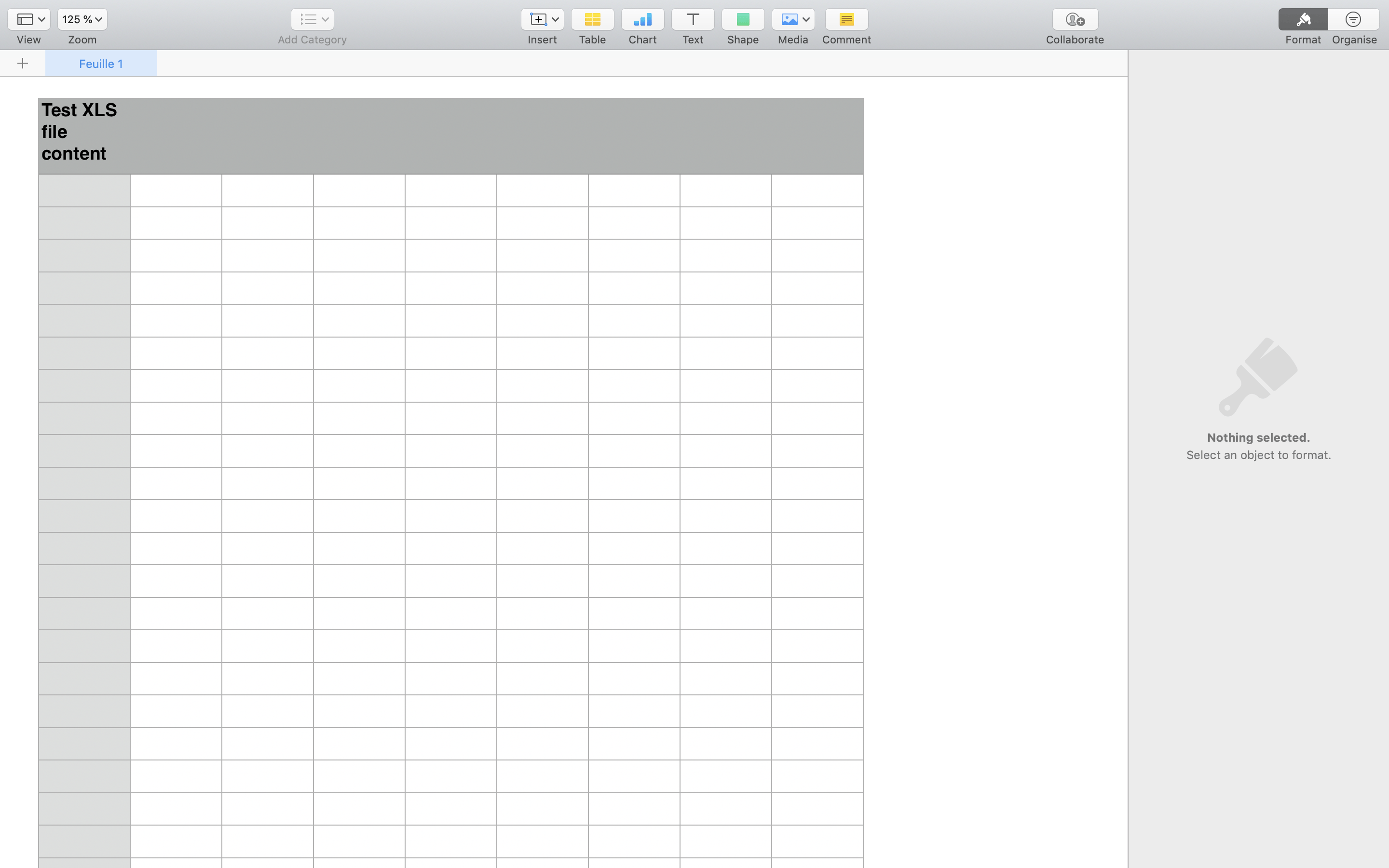
HTML
OpenDocument spreadsheets
- Associated extension:
.ods fileTypesToMatch:ods
Microsoft PowerPoint documents
- Associated extensions:
.ppt,.pptx fileTypesToMatch:ppt
.ppt file, Tika exposes the following HTML, which the crawler then passes to its recordExtractor.

HTML
OpenDocument presentations
- Associated extension:
.odp fileTypesToMatch:odp
Emails
- Associated extension:
.msg fileTypesToMatch:email
email includes all documents related to email.
The Crawler supports the Outlook Mail Message (.msg) format.
For example, Tika converts this email into the following HTML:
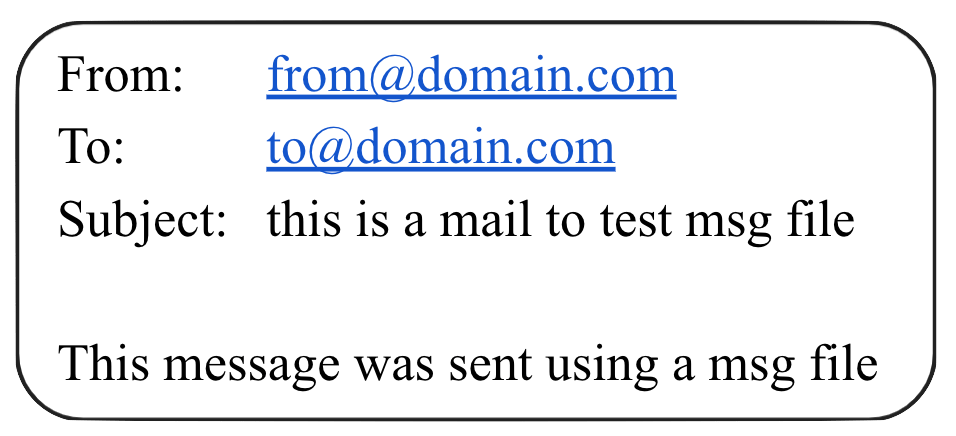
HTML