Be aware that any change to the site’s structure and attributes might affect crawling.
Use attributes that are less likely to alter, even if other aspects of the site change. For example:
- Prefer data-* global attributes
- Prefer simple CSS selectors over complex ones (with children or siblings).
Helpers
The Crawler can use helpers to extract supported JSON-LD attributes from the Article and Product schemas. To identify JSON-LD attributes on your site, use an online schema markup validator, such as: validator.schema.org. For example, to analyze the blog post jsonld.com/jsonld-webpage-vs-website, copy that URL into the validator. You’ll find theauthor information in the Webpage schema.
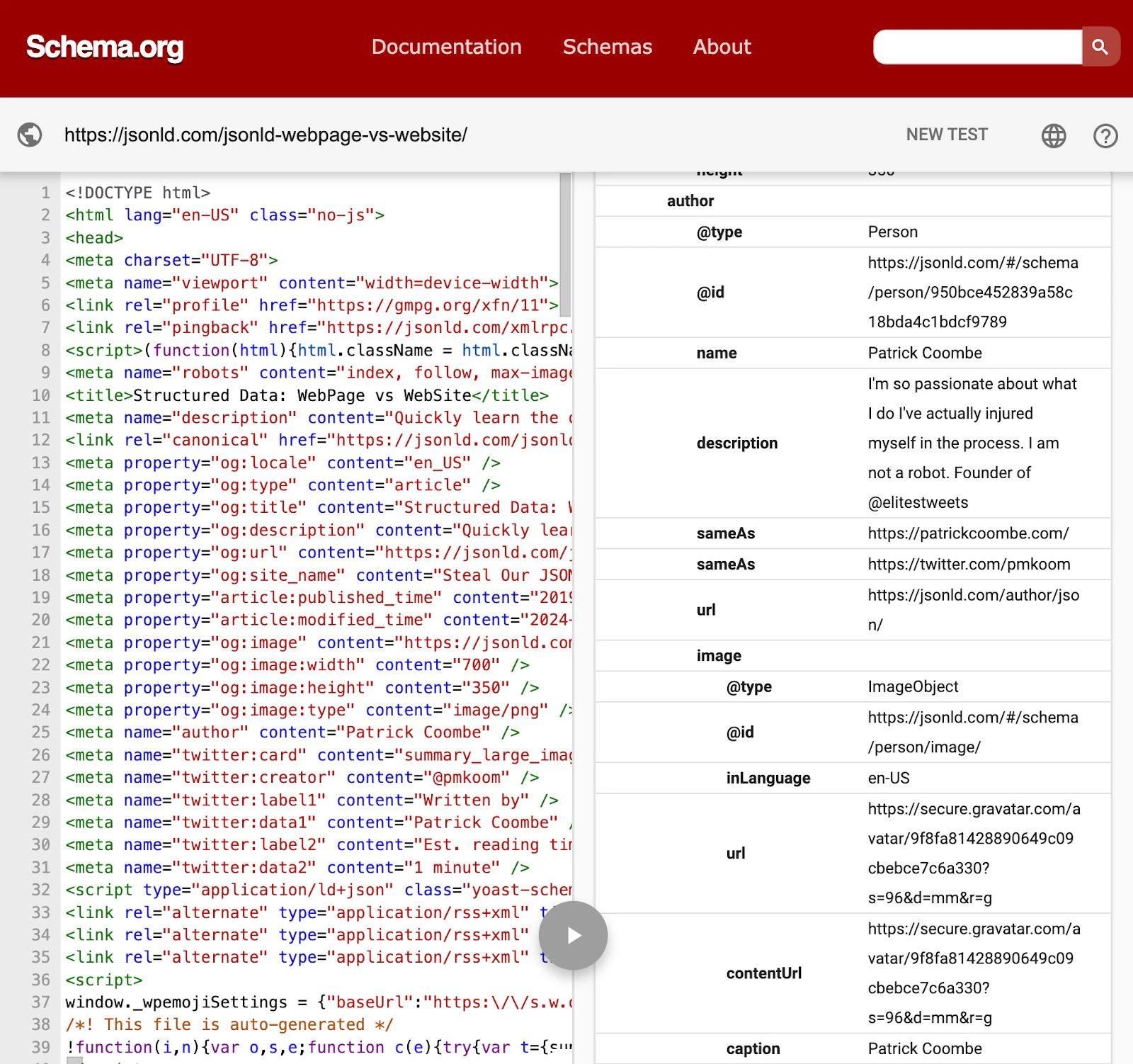
Unsupported JSON-LD attributes
To extract unsupported JSON-LD attributes and schemas in your pages, define a custom helper by adding the following instructions to your crawler’s configuration:JavaScript
Meta tags
For specifying the content a crawler should extract, meta tags are often a good start. This is because meta tags are less likely to alter during site updates or redesigns, minimizing the need to update the crawler configuration. However, meta tags might not include everything you want. If you’re trying to get information that’s not in a meta tag, like a blog post’s author, you can:- Add the missing information to your site’s meta tags
- Use helpers
- Use CSS selectors.
Extract data with meta tags
You can set up actions in your crawler’s configuration file to look for specific meta tags on your pages. The following example captures a blog post’sdescription by finding that meta tag in the head section of that page’s HTML and creating an action to tell the crawler how to extract it:
description: $("meta[name=description]").attr("content"),
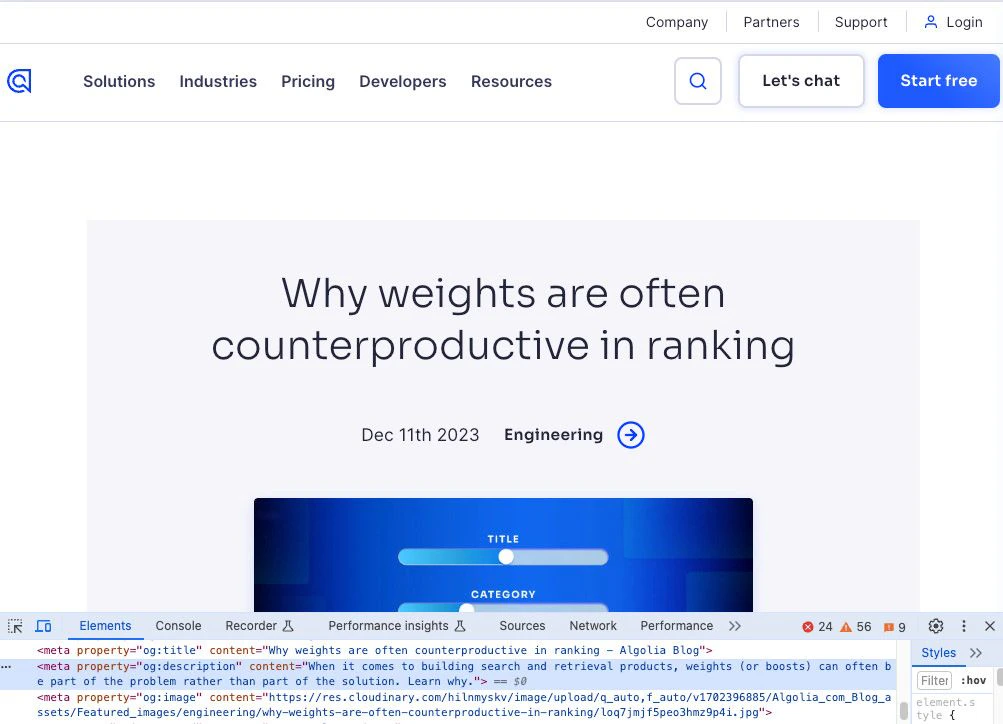
Change what you collect
Add or remove Algolia record attributes by modifying the corresponding instruction in the configuration’srecordExtractor.
For example:
- To stop capturing the
descriptionattribute for blog posts in the next crawl, delete$("meta[name=description]").attr("content")from the configuration. - To add an attribute, add a corresponding
recordExtractorwith the relevant meta tag to the configuration file.
CSS selectors
You can use CSS selectors to pinpoint the information you want to extract from thebody of a page.
For example, to extract the author name from an MDN blog post,
the appropriate CSS selector is .author.
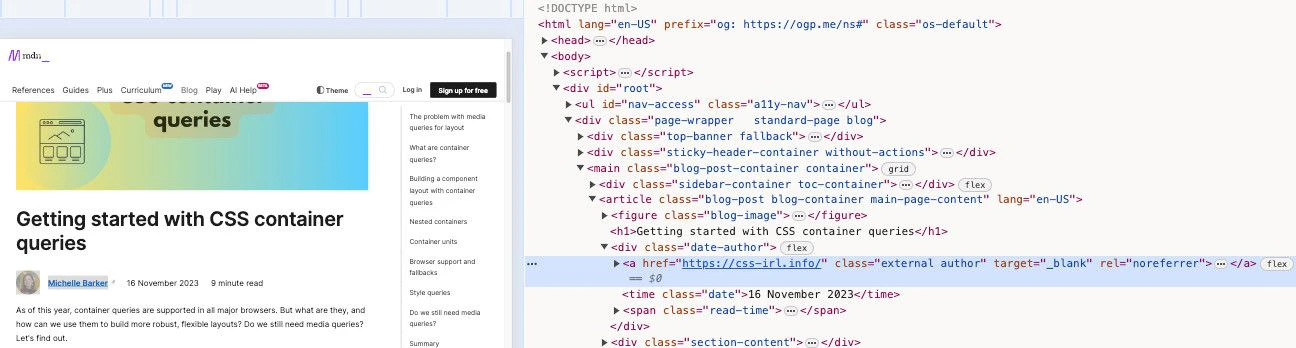
recordExtractor:
author: $(".author").text(),
For more information, see Debug CSS selectors.